NVIDIA’s current valuation is not a product of speculative fervor but a reflection of a fundamental shift in the marginal cost of intelligence. When Wall Street analysts maintain bullish stances on NVDA, they are essentially betting on the sustained divergence between traditional general-purpose computing (CPU-centric) and accelerated computing (GPU-centric). The bull case rests on three structural pillars: the transition from retrieval-based to generative architectures, the proprietary moat of the CUDA software ecosystem, and the aggressive "annual cadence" of hardware iteration that creates a moving target for competitors.
The Architectural Pivot from Retrieval to Generation
The primary driver of NVIDIA’s revenue growth is the industry-wide migration of data center workloads. For three decades, computing was largely retrieval-based. A user would request data, and a CPU would fetch it from a database. In this model, the value was in the speed of the fetch. Generative AI flips this logic; the value is now in the synthesis of new data from learned patterns. Also making news recently: The Polymer Entropy Crisis Systems Analysis of the Global Plastic Lifecycle.
Synthesis requires massive parallel processing power, a task for which the serial nature of CPUs is ill-suited. This creates a mandatory upgrade cycle. Hyperscalers (Google, Microsoft, Amazon, and Meta) cannot simply "patch" their existing infrastructure to compete in the AI era. They must replace it. This replacement cycle represents a trillion-dollar shift in global data center install base.
The efficiency gains of accelerated computing are the "carrot" for this transition. Moving a workload from a CPU to a GPU can result in a 20x improvement in energy efficiency and a 10x reduction in cost for specific AI tasks. This isn't just a performance boost; it is a fundamental reconfiguration of the cost function of the modern enterprise. More insights into this topic are detailed by Gizmodo.
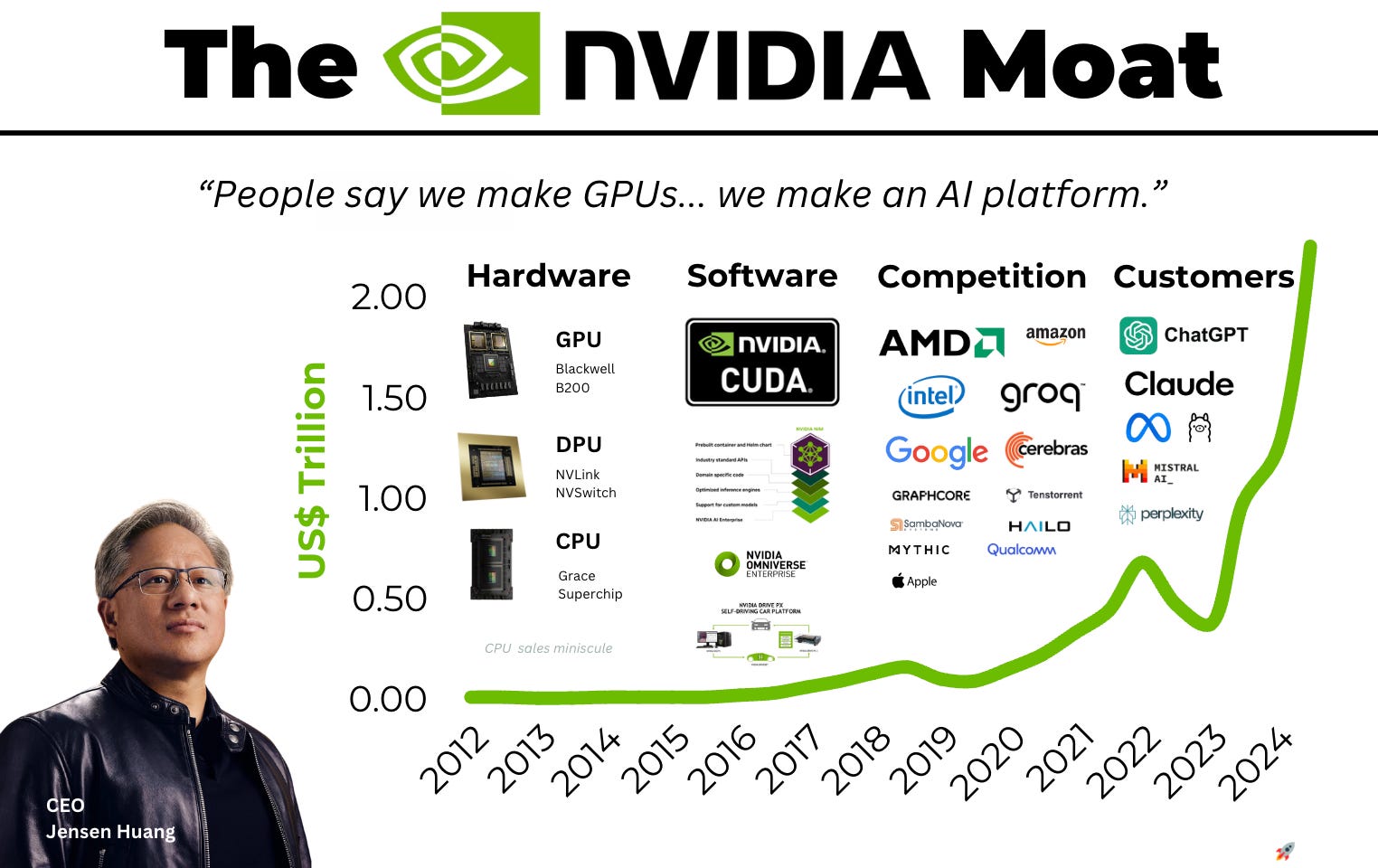
The CUDA Moat and Developer Inertia
Competitors like AMD and Intel often highlight raw hardware specifications—teraflops, memory bandwidth, and power consumption—to argue for parity. This analysis ignores the software layer. NVIDIA’s proprietary Compute Unified Device Architecture (CUDA) has been the industry standard for nearly two decades.
CUDA is not merely a programming language; it is a massive library of pre-optimized kernels and tools that allow developers to extract maximum performance from NVIDIA hardware. The "moat" here is a classic network effect:
- Developer Density: The vast majority of AI researchers and engineers are trained on CUDA.
- Library Depth: Almost every major AI framework (PyTorch, TensorFlow) is optimized for NVIDIA first.
- Deployment Reliability: For an enterprise, the risk of a "non-NVIDIA" deployment failing due to software incompatibility far outweighs any marginal savings on hardware costs.
While open-source alternatives like AMD’s ROCm or the industry-backed Triton are gaining ground, they are currently playing catch-up against a moving target. As long as NVIDIA remains the primary platform for training the "frontier models" (the largest, most capable AI systems), the software advantage remains entrenched.
The Annual Cadence and the Devaluation of Competition
NVIDIA recently shifted its product roadmap from a two-year cycle to a one-year "annual cadence." This is a strategic maneuver designed to compress the competitive window. By the time a competitor releases a chip intended to compete with NVIDIA’s current flagship (e.g., the H100), NVIDIA has already moved to the next generation (e.g., Blackwell), and announced the one after that (e.g., Rubin).
This rapid iteration creates a "Time-to-Market" penalty for any firm choosing a competitor. If a cloud provider buys a non-NVIDIA chip that is 10% cheaper but 30% slower than NVIDIA's latest release, they are effectively handicapping their customers’ ability to train models. In the AI arms race, speed to train is the only metric that matters.
Quantifying the Sovereign AI Demand
A secondary but increasingly critical pillar of the bull case is "Sovereign AI." Nation-states are beginning to view AI compute as a national utility, similar to energy or telecommunications. Countries like Singapore, France, and Japan are investing billions to build domestic AI infrastructure to ensure they aren't wholly dependent on US-based cloud providers.
This creates a new, non-cyclical buyer class. Unlike venture-backed startups that might run out of cash, or hyperscalers that might hit a CAPEX ceiling, sovereign entities operate on national security timelines. This demand provides a floor for NVIDIA’s long-term revenue, even if the private sector's "AI bubble" were to undergo a correction.
Structural Risks and Bottlenecks
A rigorous analysis must acknowledge the "Single Point of Failure" risk inherent in the NVIDIA bull case. The most significant bottleneck is not demand, but the physical manufacturing of the chips.
- TSMC Dependency: NVIDIA is fabless. It designs the chips but relies on Taiwan Semiconductor Manufacturing Company (TSMC) for production. Any geopolitical instability in the Taiwan Strait or a disruption in TSMC’s advanced packaging facilities (CoWoS) would immediately halt NVIDIA’s revenue engine.
- Power Constraints: The growth of AI data centers is hitting the hard physical limit of the electrical grid. A single H100-based cluster can consume as much power as a small city. If data centers cannot secure power permits, NVIDIA cannot sell more chips, regardless of how much demand exists.
- The Inference Shift: Currently, NVIDIA dominates the "Training" phase of AI. As the market matures, the focus will shift to "Inference" (running the models). Inference requires less raw power and can sometimes be done more efficiently on specialized, cheaper chips (ASICs) or even on the "edge" (phones and laptops). If NVIDIA cannot maintain its dominance in inference, its margins will inevitably face compression.
The CAPEX Feedback Loop
The most misunderstood aspect of the bull case is the relationship between hyperscaler spending and their own revenue. Critics argue that Microsoft and Google are "overspending" on GPUs without a clear Return on Investment (ROI).
This view ignores the defensive nature of the spend. If Microsoft stops buying GPUs, but Google continues, Microsoft risks losing its entire cloud business to a competitor that can offer faster AI training. Furthermore, these companies are using NVIDIA chips to build their own proprietary AI products (Copilot, Gemini), which drive high-margin software revenue.
The spending is a "Feedback Loop":
- Invest in GPUs.
- Build superior AI services.
- Attract more developers/users.
- Generate more cash.
- Reinvest in more GPUs to maintain the lead.
As long as this loop remains intact, NVIDIA functions as the "tax collector" for the entire AI economy.
Strategic Position for 2026 and Beyond
For a strategic observer, the play is not to look at the stock price in isolation, but to monitor the "Compute-to-GDP" ratio. We are entering an era where a nation or company's economic output is increasingly correlated with its total FLOPs (floating-point operations per second).
The immediate tactical focus should be on the transition from the Hopper architecture to the Blackwell architecture. Blackwell is not just a faster chip; it is a full-system design that integrates CPUs, GPUs, and high-speed networking (NVLink) into a single "Superchip." This integration makes it even harder for customers to "mix and match" components from other vendors.
The move for a serious analyst is to stop treating NVIDIA as a hardware company and start valuing it as the infrastructure layer of the "Intelligence Age." The ceiling for the stock is not defined by "chip sales," but by the percentage of global IT spend that migrates from legacy software to generative intelligence.
Monitor the quarterly CAPEX guidance of the "Big Four" hyperscalers. If their combined AI-related spend continues to grow at >20% annually, NVIDIA’s valuation is arguably conservative. If that spend plateaus, the market will shift from "growth at any cost" to a "margin preservation" phase, which is when the software moat will be truly tested. Until then, the architectural shift in global computing remains the strongest tailwind in the history of the technology sector.



